Speech to Code: A Near-Miss Retrospective
I spent eleven months building a coding tool, got the context problem right, and missed the idea that defined coding agents.
From August 2024 to July 2025 I built a tool called Speech to Code. 321 commits of nights and weekends. I archived the repo in October 2025, and I'm retiring its project card on this site in favor of this writeup. The honest version is more useful than the showcase.
The short version: I picked the right problem early, and I figured out one of the two things that ended up mattering, which was getting the right context in front of the model. The thing I missed was giving the model tools and letting it act. I didn't know that was even a possibility at the time. That read, write, run, verify loop is what defined coding agents, and it had been shipped in public, free and open source, sixteen months before my first commit.
What it was
A prompt composer. I'd talk into the browser, select files from my repo, add typed instructions, and the tool assembled everything into one well-structured prompt and sent it to an LLM API (OpenAI, Anthropic, or Grok). The generated code came back on screen for me to review and copy into my editor.
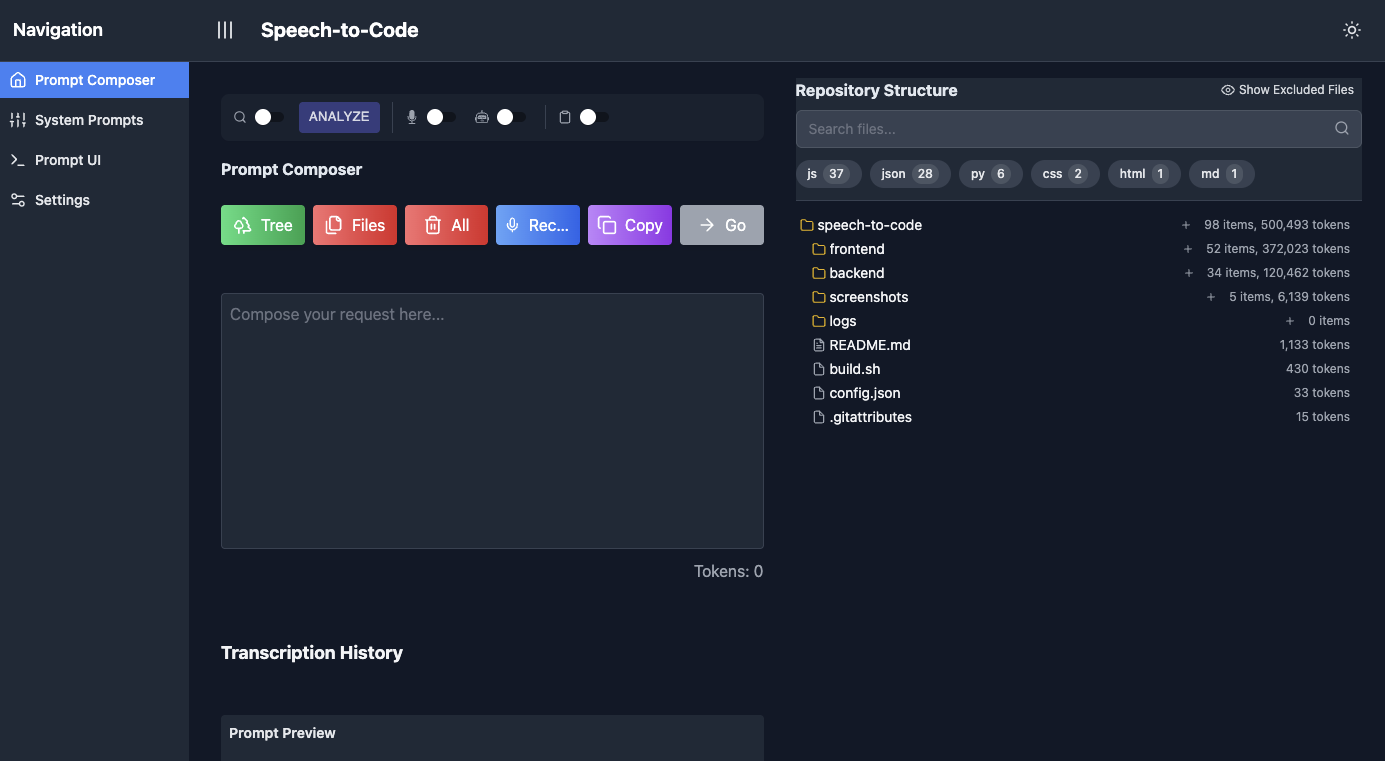
Everything that touched my repo was read-only: file tree, file contents, git info, token counts. The tool never wrote a file or ran a command. That was my job. The model wrote text, I pasted it in, ran it, read the error, and came back to compose the next prompt.
At the time I described it as the tool I used "in between copy-pasting from chat." That was exactly right. It made the copy-paste loop nicer. It never removed it.
The part I got right
I figured out pretty quickly that you can't just throw all your files into every prompt. Tokens cost money, context windows filled up fast, and models got worse when you buried them in irrelevant code. So most of the tool ended up being about context: token counts per file, ordering files by size, per-file summaries, and auto-selecting the files that were relevant to your prompt.
That last part came out of an Anthropic hackathon in October 2024. I spent it building file inference: you type a prompt, and the tool figures out which files need to be in context. Under the hood it kept a map of what lived in each file, so it could answer that question without sending your whole repo every time. I didn't have a name for it then, but it was an early, crude version of the source maps coding agents use today for exactly this problem.
By early 2025 the tool had three system prompts forming a pipeline: Validate, Plan, and Generate Agent Instructions. That last one literally produced instructions for an AI coding agent. I had decomposed the workflow correctly, then positioned my tool in front of the agent instead of building the agent.
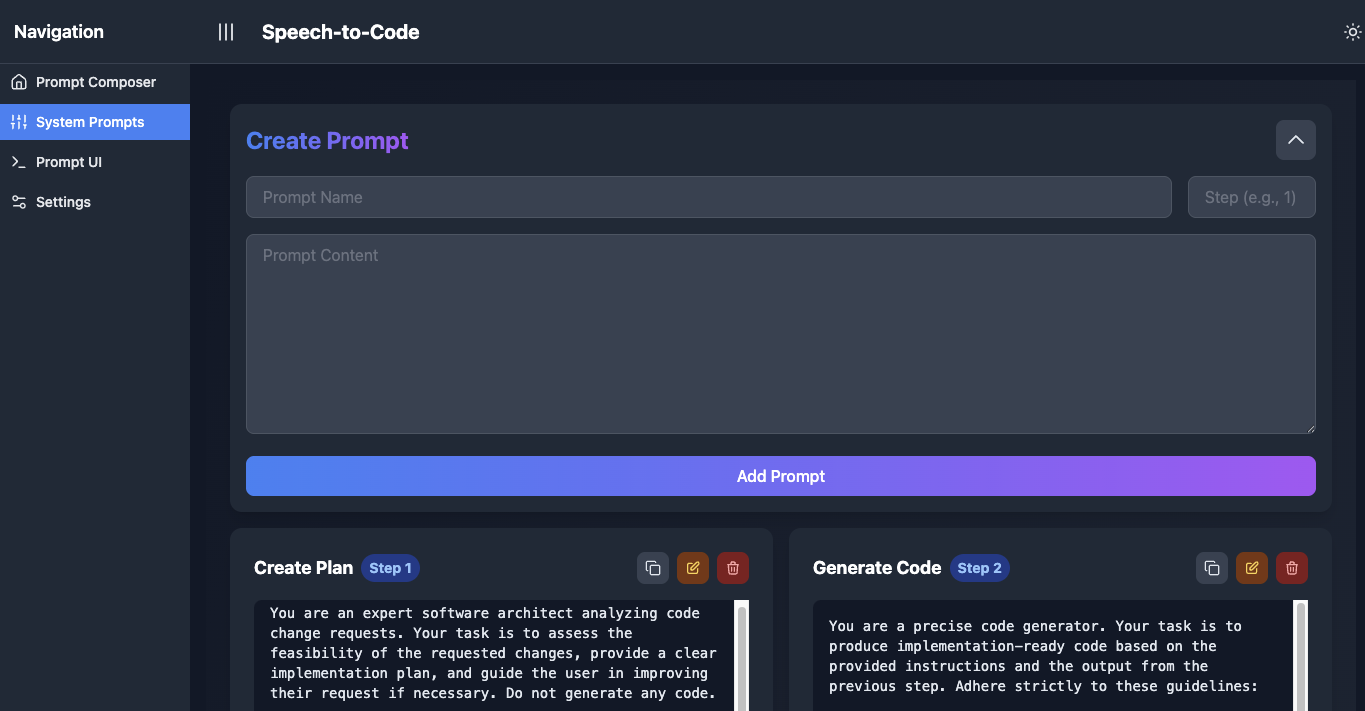
Context engineering turned out to be one of the two hard problems in this category, and I got there on my own. That part holds up.
The part I missed
I did not understand that you could give the model tools. Let it read files, write files, and run commands itself, in a loop, checking its work against errors and test output. In my head, models produced text and humans did things with the text. So I built the best version of "human does things with the text" that I could.
The loop matters more than it sounds, because it solves the reliability problem. Models in 2024 were wrong all the time, which is exactly why keeping myself in the loop felt necessary. But if the model runs the test, reads the error, and fixes its own mistake, it doesn't need to be right on the first try. I was working around the model's unreliability. The winning tools let the loop absorb it.
Two timelines
| When | The industry | Me |
|---|---|---|
| Apr 2023 | Aider ships: open-source agent that reads, writes, runs, and commits | |
| Mar 2024 | Devin announced | |
| Aug 2024 | First commit; big burst on prompt composition | |
| Oct 2024 | Anthropic hackathon: file inference | |
| Nov 2024 | Cursor ships Agent: picks its own context, runs the terminal | Big burst on context: token counts, file ordering |
| Feb 2025 | Claude Code ships as a research preview | The Validate, Plan, Generate Instructions pipeline |
| Mar 2025 | "Add coding agent output"; still no writes, no execution | |
| May 2025 | Claude Code goes GA | Almost entirely dependabot bumps |
| Oct 2025 | Repo archived |
Some fairness about that table. I was actively using these tools the whole time. Cursor and later Claude Code were in my daily workflow, and that's exactly why I eventually stopped using my own tool. And Speech to Code was never trying to be them. I built it as an improvement over copy-pasting from the ChatGPT and Claude web UIs: a faster way to assemble repo context into a prompt. That was the problem I set out to solve, and I solved it.
What I take from it
The one real lesson is about the core mechanism. Every category has one capability that is the product. For coding agents it was the tool loop, not context assembly. I spent eleven months polishing the thing next to the product. If I build in a fast-moving category again, I want to name that capability first and build the ugly version of it before polishing anything else.
The rest I'm at peace with. I was dabbling on purpose. I wasn't trying to build a coding product; I was building something for my own productivity, and it worked until better tools made it unnecessary. Some people would say that's cool. Others would say it's not ambitious enough. Either way, it was the best I could do with the time I had.
Speech to Code is archived now. It did what I built it to do, right up until the agents did it better.
Continue Reading
A year with De Quervain's tenosynovitis
My year-long experience with De Quervain's tenosynovitis as a parent of three: what caused it, what actually helped, and why the advice to just rest it never worked for me.
The old work keeps getting easier
How AI tools are compressing the time it takes to do knowledge work, and what that means for teams and individuals.